")

High Availability (HA) is crucial in Kubernetes environments to ensure applications are reliable and accessible, minimizing downtime. This blog post delves into strategies for achieving HA in Kubernetes, focusing on best practices and common challenges.
Understanding High Availability in Kubernetes
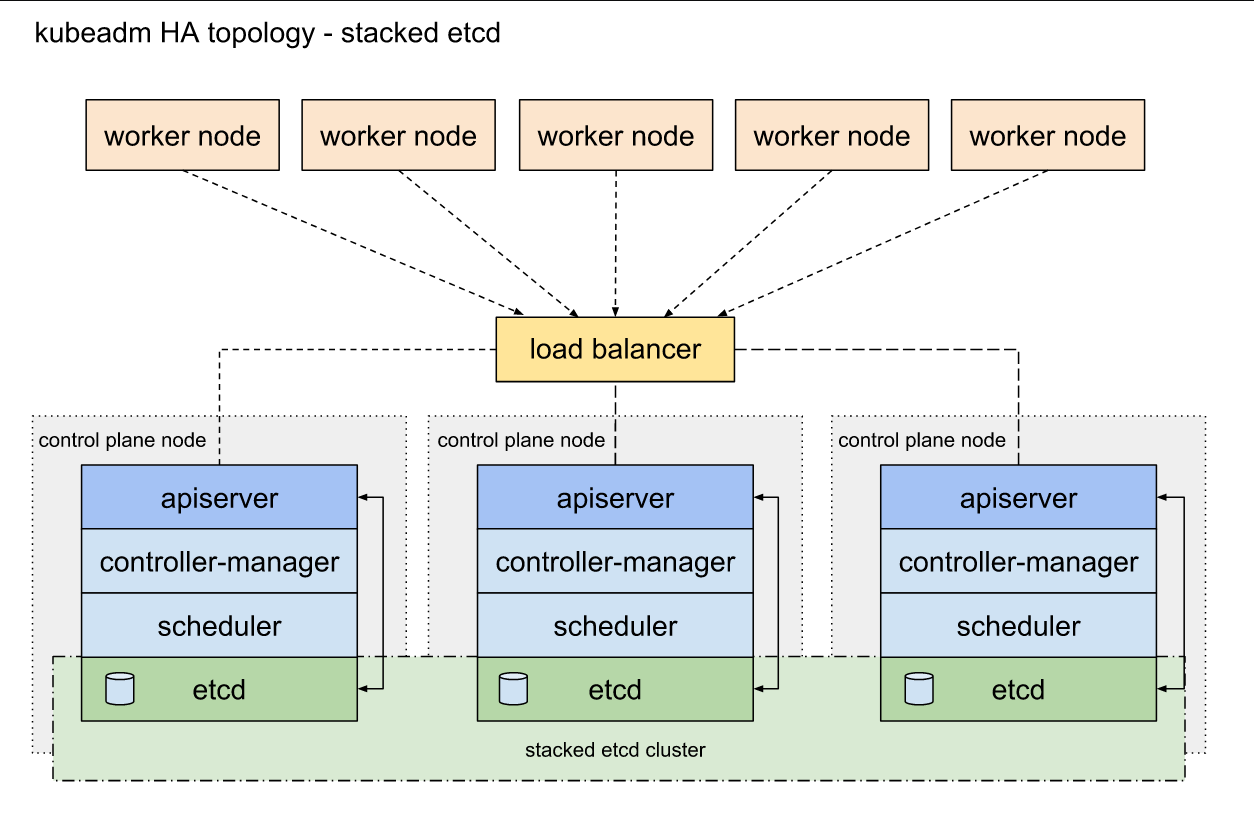
Source: https://kubernetes.io/images/kubeadm/kubeadm-ha-topology-stacked-etcd.svg
{kind=link}
Defining High Availability in Kubernetes Context
High Availability in Kubernetes is about designing a system where the applications and services are operational and accessible at all times, regardless of any failures in the components of the Kubernetes ecosystem.
The HA setup in Kubernetes is not just a fail-safe against potential downtimes but a proactive approach to maintaining continuous service availability. It’s about creating a system where the failure of a single component does not lead to the overall system's downfall.
Criticality of High Availability in Today’s IT Landscape

In the current era, where digital services form the backbone of most businesses, downtime can be incredibly costly, not just financially but also in terms of customer trust and market reputation.
High Availability goes beyond maintaining uptime; it’s about ensuring that the services are resilient enough to adapt and quickly recover from any disruptions, be it due to high traffic loads, hardware failures, or software issues.
Metrics and Standards in High Availability
The success of HA strategies in Kubernetes is often quantified using uptime and reliability metrics, typically represented as nines (e.g., 99.9% uptime, commonly referred to as “three nines”).
Achieving higher nines in availability requires meticulous planning, robust infrastructure design, and a proactive approach to monitoring and maintenance.
Key Components for High Availability
Master Node Redundancy
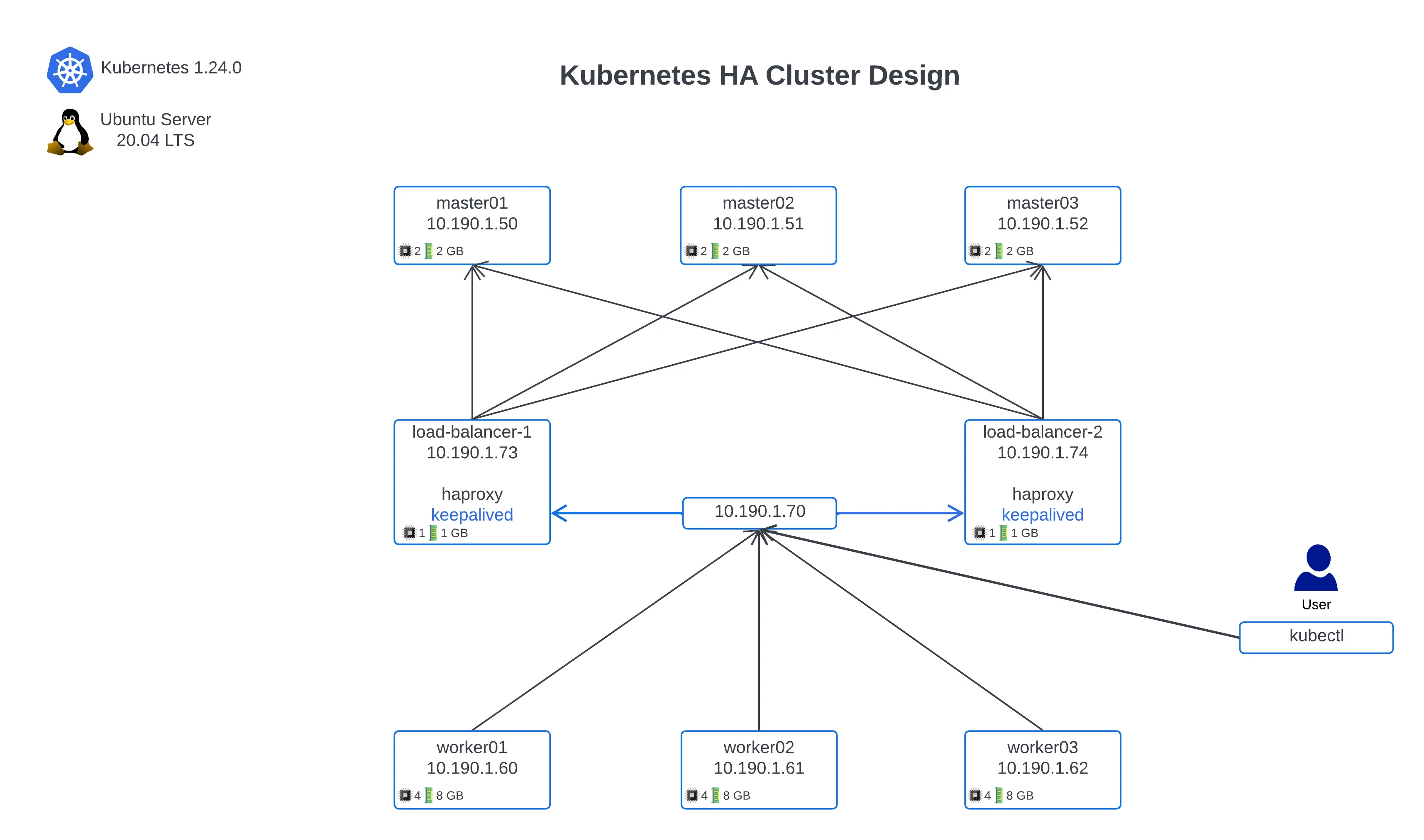
Source: https://medium.com/devopsturkiye/kubernetes-1-24-ha-cluster-kurulumu-fefeec1ce5ea
Having multiple master nodes in different physical locations or availability zones is essential. This setup ensures that if one master node fails, others can take over, keeping the cluster operational.
Automated failover mechanisms should be in place to seamlessly switch control to a healthy master node without manual intervention.
Worker Node Reliability
Worker nodes, where the actual workloads run, must also be reliable. This involves using replication and redundancy strategies to ensure that if a worker node fails, its workload can be quickly shifted to another node.
Regular health checks and self-healing mechanisms are crucial for identifying and addressing issues in worker nodes promptly.
Robust Networking
A highly available Kubernetes cluster requires a robust networking setup. This includes implementing network redundancy and ensuring that network components like load balancers, routers, and switches are fault-tolerant.
Network policies should be configured to manage traffic flow effectively, preventing bottlenecks and single points of failure.
Persistent Storage Management
Persistent storage solutions must be resilient and redundant. Using distributed storage systems can ensure data remains accessible even if one storage node fails.
Implement storage solutions that support dynamic provisioning and allow for easy scaling to meet changing storage demands.
Load Balancing and Service Discovery
Implementing load balancing helps distribute traffic evenly across multiple nodes, preventing any single node from becoming a bottleneck.
Service discovery mechanisms ensure that applications and services can locate and communicate with each other efficiently, even as instances are created or terminated.
Strategies for High Availability
Cluster Federation
Cluster federation involves linking multiple Kubernetes clusters together. This not only provides redundancy but also allows for distributing workloads across different geographical regions for better availability and performance.
Federated clusters can be used to implement global failover strategies, where if one cluster becomes unavailable, another can take over its workload.
Auto-Scaling
Implementing auto-scaling for both pods and nodes ensures the cluster can handle varying loads without human intervention. This is crucial for maintaining HA, especially during unexpected traffic spikes.
Horizontal Pod Autoscaler (HPA) and Cluster Autoscaler are vital tools in Kubernetes for achieving effective auto-scaling.
Monitoring and Alerting
Continuous monitoring of cluster components and workloads is essential for high availability. Monitoring tools can provide real-time insights into the health and performance of the cluster.
Coupled with an effective alerting system, monitoring can enable quick response to potential issues before they escalate into significant problems.
Disaster Recovery Planning
Having a disaster recovery plan is critical for HA. This involves regular backups of critical data and the ability to quickly restore operations in the event of a major failure.
Testing disaster recovery procedures regularly ensures they are effective and that the team is prepared to execute them under pressure.
Regular Updates and Patch Management
Keeping Kubernetes and its components up to date with the latest security patches and updates is vital for avoiding vulnerabilities that can compromise availability.
Automated update and patch management processes can help in maintaining the cluster's security and performance without significant downtime.
Challenges in Achieving High Availability
Complexity of Kubernetes Architecture
The inherent complexity of Kubernetes can be a challenge in achieving HA. Understanding and managing various components and their interactions require significant expertise.
Investing in training and knowledge-sharing can help teams better navigate this complexity and implement effective HA strategies.
Resource Management
Efficient resource management is critical for HA. Over-provisioning can lead to wasted resources, while under-provisioning can result in performance bottlenecks and potential downtime.
Implementing resource quotas and limits, along with effective monitoring, can help in balancing resource utilization optimally.
Handling Stateful Applications
Managing stateful applications in Kubernetes, which require persistent storage and specific network identities, poses additional challenges for HA.
Using StatefulSets and persistent volume claims (PVCs) can help in managing stateful workloads effectively while maintaining high availability.
Security Considerations
Security is a crucial aspect of HA. Vulnerabilities or security breaches can lead to downtime and loss of availability.
Implementing robust security practices, including network security, access controls, and regular security audits, is essential for maintaining HA.
Conclusion
Achieving high availability in Kubernetes is a multifaceted endeavor involving careful planning, robust infrastructure, and continuous monitoring. By focusing on key components and strategies, and addressing common challenges, organizations can ensure their Kubernetes clusters remain resilient, efficient, and highly available.
Read our latest Blogpost
